이 글은 CloudNet@ 팀 gasida님의 스터디 DOIK 2기 내용 및 실습으로 작성된 글입니다.
K8S Operator 란?
- 사용자 정의 리소스를 사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 익스텐션
- K8S Operator는 CR 유형을 감시하고 애플리케이션별 작업을 수행하여 현재 상태를 해당 리소스(사용자 정의)에서 원하는 상태와 일치
- 애플리케이션이 실행되는 동안 이를 지속적으로 모니터링하고, 시간 경과에 따라 자동으로 데이터 백업, 장애 복구, 애플리케이션 업그레이드 작업을 할 수 있음
→ 리소스: 직접 정의한 CRD(Custom Resource Definition)
→ 감시: CRD 상태 변화를 감지
→ 상태 일치: Object가 원하는 상태가 되도록 로직을 수행하는 operator의 핵심 부분, Reconciler라는 함수가 이를 수행
- CRD (Custom Resource Definition): 오퍼레이터로 사용할 상태 관리용 객체들의 Spec을 정의
- CR (Custom Resource): CRD의 Spec을 지키는 객체들의 실제 상태 데이터 조합
- CC (Custom Controller): CR의 상태를 기준으로 현재 상태를 규정한 상태로 처리하기 위한 컨트롤 루프
- Operator manager Container 구조

◎ Resource 감지
- K8S Cache는 Kubernetes API Server의 부하를 줄이기 위해 API Server로부터 가져온 정보를 캐싱하는 역할
- Informer는 Controller가 관리해야하는 리소스를 Watch하여 Object(resource)의 생성/삭제/변경 등의 변화 Event를 전달받음
- Informer는 Object(resource)의 Name 및 Object(resource)가 위치한 Namespace 정보만 추출
- Work queue는 Informer에 존재하는 Object(resource)의 Event Name/Namespace 정보 저장
→ 각 컨트롤러를 위한 전용 work queue가 존재
- K8S Client는 컨트롤러가 K8S API 서버와 통신하기 위한 역할을 수행하고, manager에 하나의 client가 존재하며 다수의 컨트롤러가 하나의 K8S client Instance를 공유하여 이용
- Client의 Object(resource) write요청은 K8S API server에게 바로 전달하나, Object read 요청은 K8S cache에게 전달
◎ 로직 수행
- Reconciler는 work queue에 저장된 Event가 발생한 Object(resource)의 Namespace/Name 정보를 가져옴
- 가지고 온 정보로 Client를 이용하여 Object(resource)의 spec과 status를 제어하여 일치시키는 역할을 수행
- 제어에 성공하였을 경우 해당 Object(resource)의 정보를 폐기하지만, 제어에 실패하였을 경우 제어를 성공할 때까지 work queue에 넣고 빼기를 반복
MySQL Operator for K8S 설치
# Repo 추가
helm repo add mysql-operator https://mysql.github.io/mysql-operator/
helm repo update
# 실험 버전 설치 : 차트 버전(--version 2.1.0), 애플리케이션 버전(8.1.0-2.1.4)
helm install mysql-operator mysql-operator/mysql-operator --namespace mysql-operator --create-namespace --version 2.1.0
helm get manifest mysql-operator -n mysql-operator
# 설치 확인
kubectl get deploy,pod -n mysql-operator
# CRD 확인
kubectl get crd | egrep 'mysql|zalando'
## (참고) CRD 상세 정보 확인
kubectl describe crd innodbclusters.mysql.oracle.com



MySQL Inno DB란?
- MySQL에서 사용하는 데이터베이스 엔진
- 트랜잭션 세이프 스토리지 엔진으로서 대용량 데이터를 처리할 때 많은 장점을 갖고 있음
- commit, rollback, 장애복구, row-level locking, 외래키 등의 기능을 제공
◈ 데이터베이스 엔진?
- DBMS가 데이터베이스에 대해 데이터를 삽입, 추출, 업데이트 및 삭제하는데 사용하는 기본 소프트웨어 컴포넌트
- 데이터베이스 엔진을 조작할 때 DBMS 고유의 사용자 인터페이스를 이용하는 방법과 포트 번호를 이용하는 방법이 존재
- 대부분의 DBMS는 고유의 사용자 인터페이스를 통하지 않고, 사용자가 내장된 엔진과 상호작용이 가능한 자신만의 API를 포함
- InnoDB 구조 및 아키텍처

- Inno DB는 In-memory 구조로, 데이터와 인덱스를 메모리에 캐싱하기 위한 버퍼 풀이라는 저장 영역을 유지 및 관리
- 주요 구성은 Buffer Pool, Log Buffer, Chanfge Buffer 등으로 구성
1. Inno DB Buffer Pool
- Inno DB 스토리지 엔진에서 가장 핵심이며, 디스크의 데이터 파일이나 정보를 메모리에 캐시하는 공간
- SELECT 시에 버퍼 캐시에 해당 페이지가 없다면 ibdata를 뒤져 버퍼풀에 기록하고 결과값을 반환
- INSERT 시 해당 데이터가 캐시되어있지 않다면, 캐시 생성 및 물리적인 파일에 내용 기술
- 버퍼풀은 쓰기 작업을 지연시키며 일괄적으로 처리할 수 있게 하는 버퍼 역할도 같이 함
2. Undo Log
- Undo는 데이터가 변경되었을 때(update, delete 등) 이전의 데이터를 보관하는 곳
- Update 실행 시, 실제 데이터 파일에는 변경된 데이터가 저장되며 이전 데이터를 undo 영역에 백업 시키며, 해당 상태에서 commit을 하면 상태가 유지 됨. rollback을 시키면 undo 영역에 백업된 데이터를 데이터 파일로 복구 시킴
3. Insert Buffer
- 인덱스 변경이 필요할 때 인덱스 페이지가 버퍼 풀에 있으면 업데이트를 바로 수행하며 그렇지 않을 경우 임시공간에 저장하고 사용자에게 결과를 반환하는 형태로 성능을 향상 시키는데 이때 사용하는 임시 메모리 공간이 Insert Buffer임
- Insert Buffer에 임시로 저장되는 인덱스 레코드 조각은 이후 백그라운드 버퍼 머지 스레드에 의해 병합됨
4. Redo Log 및 Log Buffer
- 쿼리로 데이터를 변경할 때 순차적으로 변경된 내용을 기록하는 파일을 redo log라고 함
- 대용량 작업 시, redo log 작업의 문제를 보완하기 위해 최대한 ACID 속성을 보정하는 수준으로 버퍼링하게 되며 log buffer는 redo buffering에 사용되는 공간
MySQL Inno DB Cluster 설치
# 파라미터 파일 생성
cat <<EOT> mycnf-values.yaml
credentials:
root:
password: sakila
serverConfig:
mycnf: |
[mysqld]
max_connections=300
default_authentication_plugin=mysql_native_password
tls:
useSelfSigned: true
EOT
helm install mycluster mysql-operator/mysql-innodbcluster --namespace mysql-cluster --version 2.1.0 -f mycnf-values.yaml --create-namespace
helm get values mycluster -n mysql-cluster
helm get manifest mycluster -n mysql-cluster
# 설치 확인
kubectl get innodbcluster,sts,pod,pvc,svc,pdb,all -n mysql-cluster
kubectl df-pv
kubectl resource-capacity
# MySQL InnoDB Cluster 구성요소 확인
kubectl get InnoDBCluster -n mysql-cluster
# 이벤트 확인
kubectl describe innodbcluster -n mysql-cluster | grep Events: -A30
# MySQL InnoDB Cluster 초기 설정 확인
kubectl get configmap -n mysql-cluster mycluster-initconf -o json | jq -r '.data["my.cnf.in"]'
kubectl get configmap -n mysql-cluster mycluster-initconf -o yaml | yh
kubectl describe configmap -n mysql-cluster mycluster-initconf
- Helm Chart의 Default Vlaues 확인
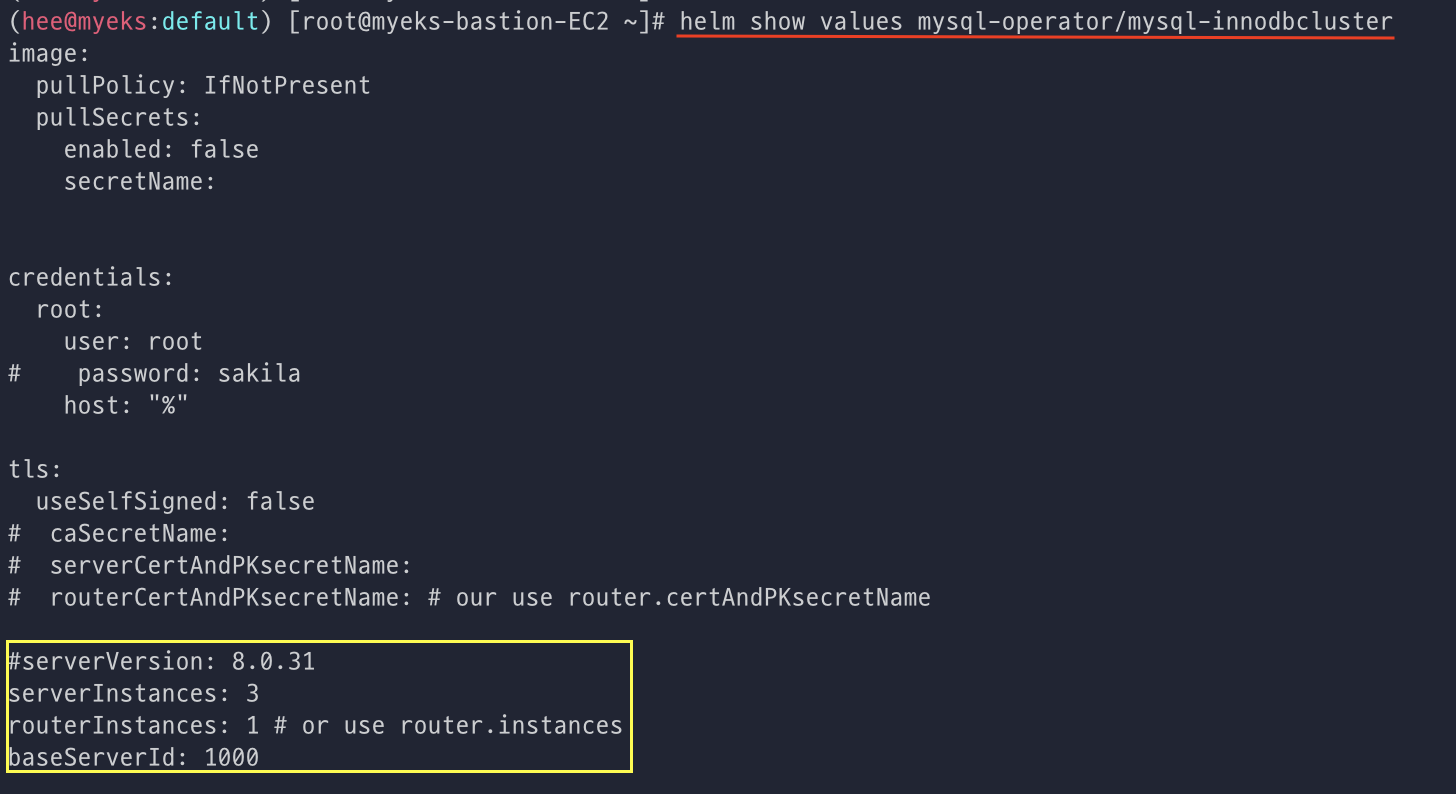
yaml 파일을 생성한 후에 helm install 명령어를 통해 설치 후 확인

설치된 DB Pod, pvc, svc, 등 전체적으로 확인


- 'gtid_mode=ON' = 그룹 복제 모드 사용을 위해서 GTID 활성화
- 'relay_log_info_repository=TABLE' = 일관성을 위해 릴레이 로그 파일이 아닌 테이블에 저장

- 기본값은 151이나, 위에서 helm 으로 설치할 때 300으로 변경하여 설치함.
서버 인스턴스 확인하고 3개의 Node에 Pod가 정상적으로 생성되었는지 확인 후에 프로브 값도 확인.

서버 인스턴스가 사용하는 PV 확인 (인스턴스에 배포한 게 없어서 그런가 available 값이 여유가 있다ㅎㅎ)

서버 인스턴스 접속을 위해 cluster 정보 확인

라우터 인스턴스 (Deployment) 확인 1대의 Pod가 있을 것

max_connetction 설정 값 확인
- MySQL 라우터를 통해 MySQL 파트 접속 후 parameter값 확인

MySQL 접속 방법
MySQL 라우터 접속을 위한 서비스와 Pod 접속을 위한 서비스 정보 확인 후 Pod에 접속 후 DNS 쿼리 수행

도메인 주소로 접근 시 MySQL 라우터를 통해 Pod로 접속되며, Headless 서비스 주소로 개별 Pod로 접속하기 위하여 DNS쿼리를 실행했다.
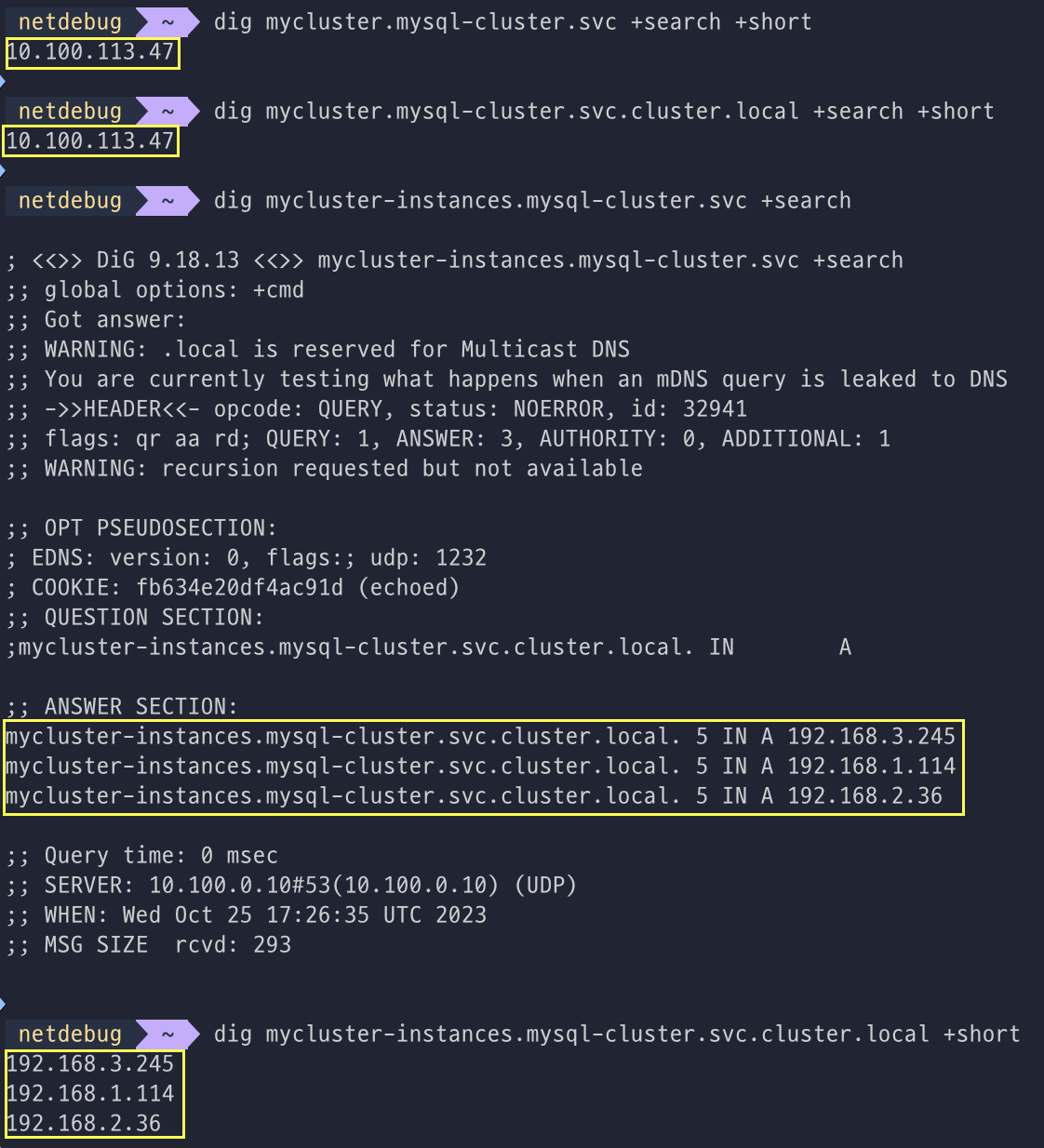
Pod마다 가지고 있는 고유의 SRV레코드가 있으며, 도메인 주소로 접속할 경우에 MySQL Pod로 접속된다.

접속 주소 변수를 지정해주고, MySQL 라우터를 통해 Pod 접속해보고, 개별 Pod로도 접속을 해봤다.

MySQL Tutorial 실습
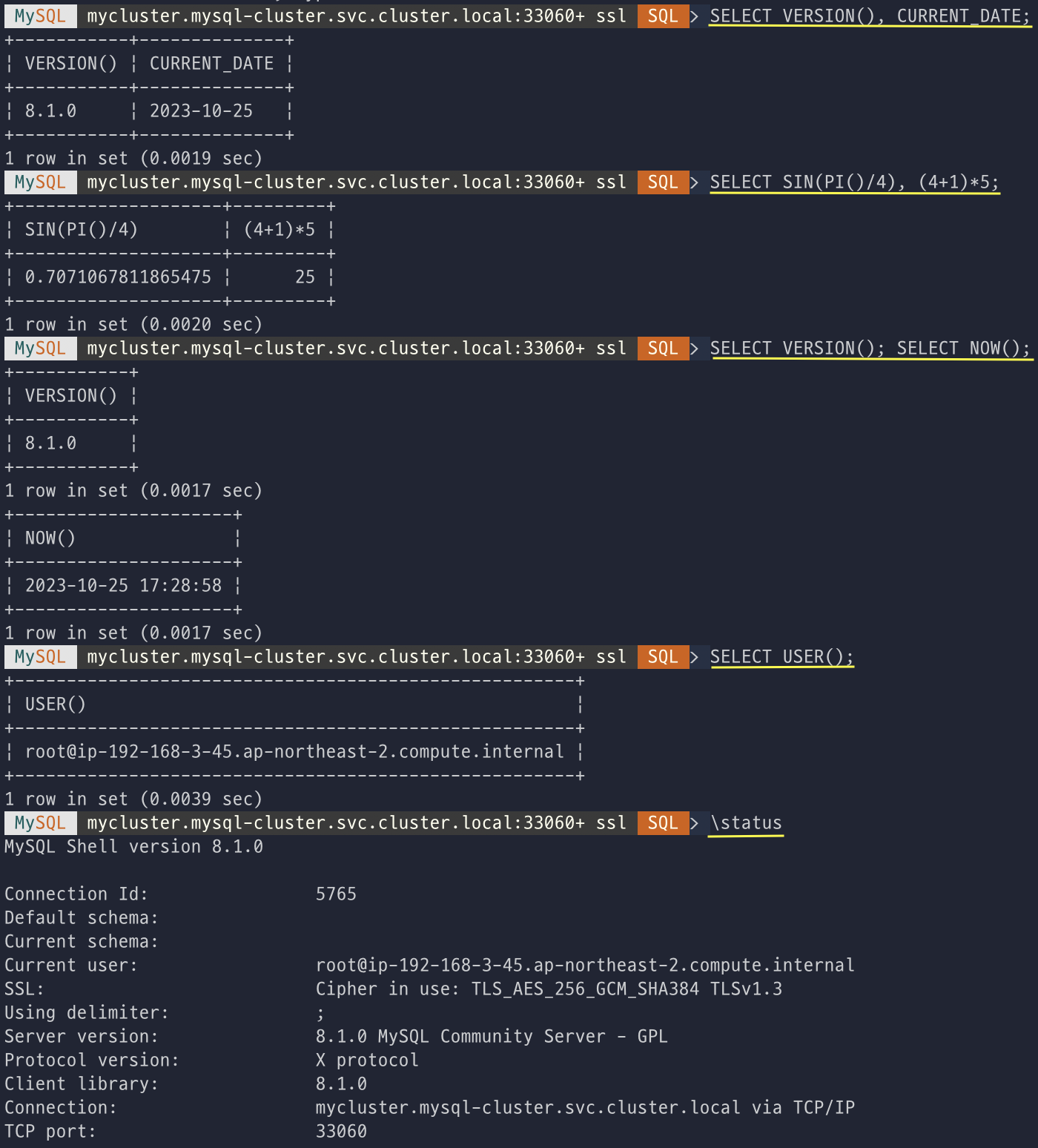
# 접속
kubectl exec -it -n mysql-operator deploy/mysql-operator -- mysqlsh mysqlx://root@$MIC --password=sakila --sqlx
# 버전 및 날짜 확인
SELECT VERSION(), CURRENT_DATE;
# 버전과 현재 시간을 각각 실행
SELECT VERSION(); SELECT NOW();
# 접속 유저 정보 확인
SELECT USER();
# 상태 정보
\status
# 사용 가능 문자 셋
SHOW CHARACTER SET;


참고
https://kubernetes.io/ko/docs/concepts/extend-kubernetes/operator/
https://www.redhat.com/ko/topics/containers/what-is-a-kubernetes-operator
https://togomi.tistory.com/28
https://seongjin.me/kubernetes-core-concepts/
https://ssup2.github.io/programming/Kubernetes_Kubebuilder/
https://neocan.tistory.com/396
'CloudNetaStudy > [Study] DOIK' 카테고리의 다른 글
| [5주차] Kafka & Strimzi Operator (0) | 2023.11.17 |
|---|---|
| [4주차] Percona Operator for MongoDB (2) | 2023.11.06 |
| [3주차] Cloud Native PostgreSQL (0) | 2023.11.01 |
| [2주차] 실습 환경 세팅하기 (0) | 2023.10.25 |
| [1주차] Kubernetes 기초 (0) | 2023.10.17 |