이 글은 CloudNet@ 팀 gasida님의 스터디 DOIK 2기 내용 및 실습으로 작성된 글입니다.
What is Kafka?

웹사이트, 어플리케이션, 센서 등에 취합한 데이터를 스트림 파이프라인을 통해 실시간으로 관리하고 보내기 위한 분산 스트리밍 플랫폼이다.
데이터를 생성하는 어플리케이션과 데이터를 소비하는 어플리케이션 간의 중재자 역할을 함으로써 데이터의 전송 제어, 처리, 관리 역할을 한다. 카프카 시스템은 여러 요소(노드)와 함께 구성될 수 있어 카프카 클러스터 라고 하기도 하는데 다른 메시징 시스템과 마찬가지로 어플리케이션과 서버 간의 비동기 데이터 교환을 용이하게 하고, 하루에 수 조개의 이벤트 처리가 가능하게 하는 역할을 한다.
카프카는 데이터 파이프 라인을 만들 때 주로 사용되는 오픈소스 솔루션이다.
Kafka 아키텍처 및 주요 개념 및 용어

Kafka 클러스터를 중심으로 프로듀서(Producer)와 컨슈머(Consumer)가 데이터를 Push하고 Pull하는 구조이다. 프로듀서(Producer), 컨슈머(Consumer)는 각기 다른 프로세스에서 비동기로 동작하고 있다.

프로듀서(Producer)가 데이터를 Kafka에 적재하고 있으며, 저장된 데이터를 컨슈머 그룹(Consumer Group) A와 B가 각각 자신이 처리해야할 Topic Foo와 Bar를 가져온다. Foo와 Bar는 각각 3개의 파티션으로 나뉘어져 있으며, 각각의 파티션들은 3개의 복제본으로 복제가 된다. 3개의 복제본 중 하나의 리더가 선출되고, 선출된 리더가 모든 데이터의 읽기, 쓰기, 연산을 담당한다. 파티션들은 운영 도중 그 수를 늘릴 수 있지만 절대 줄일 수는 없다. 그렇기 때문에 파티션을 늘리고자 할때는 파티션을 줄일 수 없는 부분을 충분히 고려한 다음에 늘려야 한다.
Kafka 클러스터에서 데이터를 가져오게 될 때는 컨슈머 그룹(Consumer Group)단위로 가져오게 된다. 컨슈터 그룹(Consumer Group)은 자신이 가져와야하는 토픽 안의 파티션의 데이터를 Pull하게 되고, 각각 컨슈퍼 그룹 안의 컨슈머들이 파티션의 수 만큼 데이터를 처리한다.
◈ 프로듀서(Producer): 데이터를 발생시키고 카프카 클러스터(Kafka Cluster)에 적재하는 프로세스, 메시지(이벤트)를 발생하여 Wirte하는 주체
◈ 컨슈머(Consumer): 메시지(이벤트)를 구독하여 Read하는 주체
◈ 컨슈머 그룹(Consumer Group): 컨슈머 집합을 구성하는 단위, 컨슈머 그룹으로 데이터를 처리하며, 컨슈머 그룹 안의 컨슈머 수만큼 파티션의 데이터를 분산처리 함.
◈ 카프카 클러스터(Kafka Cluster): 카프카 서버로 이루어진 클러스터를 의미
- 브로커(Broker): 각각의 카프카(Kafka) 서버, 동일 노드에 여러 브로커를 띄울 수 있음.
- 주키퍼(Zookeeper): 분산 코디네이션 시스템, 카프카 브로커를 하나의 클로스터로 코디네이팅을 하는 역할을 하며 카프카 클러스터의 리더(Leader)를 발탁하는 방식도 주키퍼가 제공하는 기능을 이용함.
- 토픽(Topic): 카프카 클러스터에 데이터를 관리할 시에 기준이 되는 개념, 카프카 클러스터에서 여러 개를 만들 수 있고 토픽은 1개 이상의 파티션(Partition)으로 구성되어 있음.
- 파티션(Partition): 각 토픽 당 데이터를 분산처리 하는 단위, 카프카에서 토픽 안에 파티션을 나누어 그 수대로 데이터를 분산 처리 함. 카프카 옵션에서 지정한 replica의 수만큼 파티션이 각 서버들에게 복제 됨.
- 리더, 팔로워(Leader, Follower): 카프카에서는 각 파티션당 복제된 파티션 중에 하나의 리더가 선출되고, 리더는 모든 읽기, 쓰기 연산을 담당함. 리더를 제외한 나머지는 팔로워가 되고, 팔로워들은 리더의 데이터를 복사하는 역할을 함.
<그림1>에서 Producer가 데이터를 카프카에 적재하고, 저장된 데이터를 Consmuer Group A,B가 각각 자신이 처리해야 될 Topic Foo, Bar를 가지고 온다.
Foo와 Bar는 각각 3개의 파티션으로 나뉘어져 있으며, 이 각각의 파티션들은 3개의 복제본으로 복제가 된다. 3개의 복제본 중 하나의 리더가 선출되고(민트색) 리더가 모든 데이터의 읽기, 쓰기, 연산을 담당한다. 위에서 말한대로 이 파티션은 늘릴 수는 있지만, 절대 줄일 수는 없다. 파티션을 늘리고자 할 때는 파티션을 줄일 수 없음을 고려해서 결정해야한다.
카프카 클러스터에서 데이터를 가져올 때는 컨슈머 그룹(Consumer Group)단위로 가져온다. 컨슈머 그룹은 자신이 가져와야하는 토픽 안의 파티션에 데이터를 Pull하고, 각 컨슈머 그룹안의 컨슈머들이 나뉘어져 있는 파티션만큼 데이터를 처리하게 된다.

카프카에서 읽기, 쓰기, 연산은 카프카 클러스터 내의 리더 파티션들에게만 적용된다. 각 파티션 리더들(민트색)은 파티션들에게 프로듀서가 쓰기 연산을 진행한다. 그리고 리더 파티션에 쓰기가 진행되고 난 후 업데이트 된 데이터는 각 파티션들의 복제본에 복제를 하게된다.
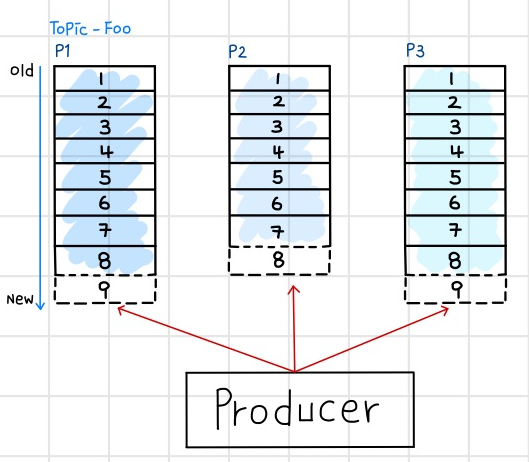
카프카 데이터는 순차적으로 데이터를 디스크에 저장한다. 그렇기에 프로듀서는 순차적으로 저장된 데이터 뒤에 붙이는 append 형식으로 write 연산을 진행하게 된다. 이 때 파티션들은 각각의 데이터가 순차적으로 집합된 오프셋(offset)으로 구성되어 있다.

컨슈머 그룹의 각 컨슈머들은 파티션의 오프셋을 기준으로 데이터를 순차적으로 처리한다(FIFO). 컨슈머들은 컨슈머 그룹으로 나뉘어서 데이터를 분산 처리하게 되고 같은 컨슈머 그룹 내에 있는 컨슈머끼리 같은 파티션의 데이터를 처리 할 수 없다. 파티션에 저장되어 있는 데이터들은 순차적으로 데이터가 저장되어 있고, 데이터들은 설정값에 따라 데이터를 디스크에 보관하게 된다. (2.x기준 default 7Days)

만약 컨슈머와 파티션 개수가 같다면 컨슈머는 각 파티션을 1:1로 맡게 된다. 컨슈머 그룹 안의 컨슈머의 개수가 파티션의 개수보다 적을 경우 컨슈머 중 하나가 남는 파티션의 데이터를 처리하게 된다. 만일 컨슈머의 개수가 파티션의 개수보다 많을 경우 남는 컨슈머는 파티션이 개수가 많아질 때까지 대기하게 된다.
실습
Strimzi Operator 설치 with Helm
먼저 kafka ns를 생성해주고 helm repo 추가 후에 확인해준다. (아까 repo 추가해서 skipping 됨)
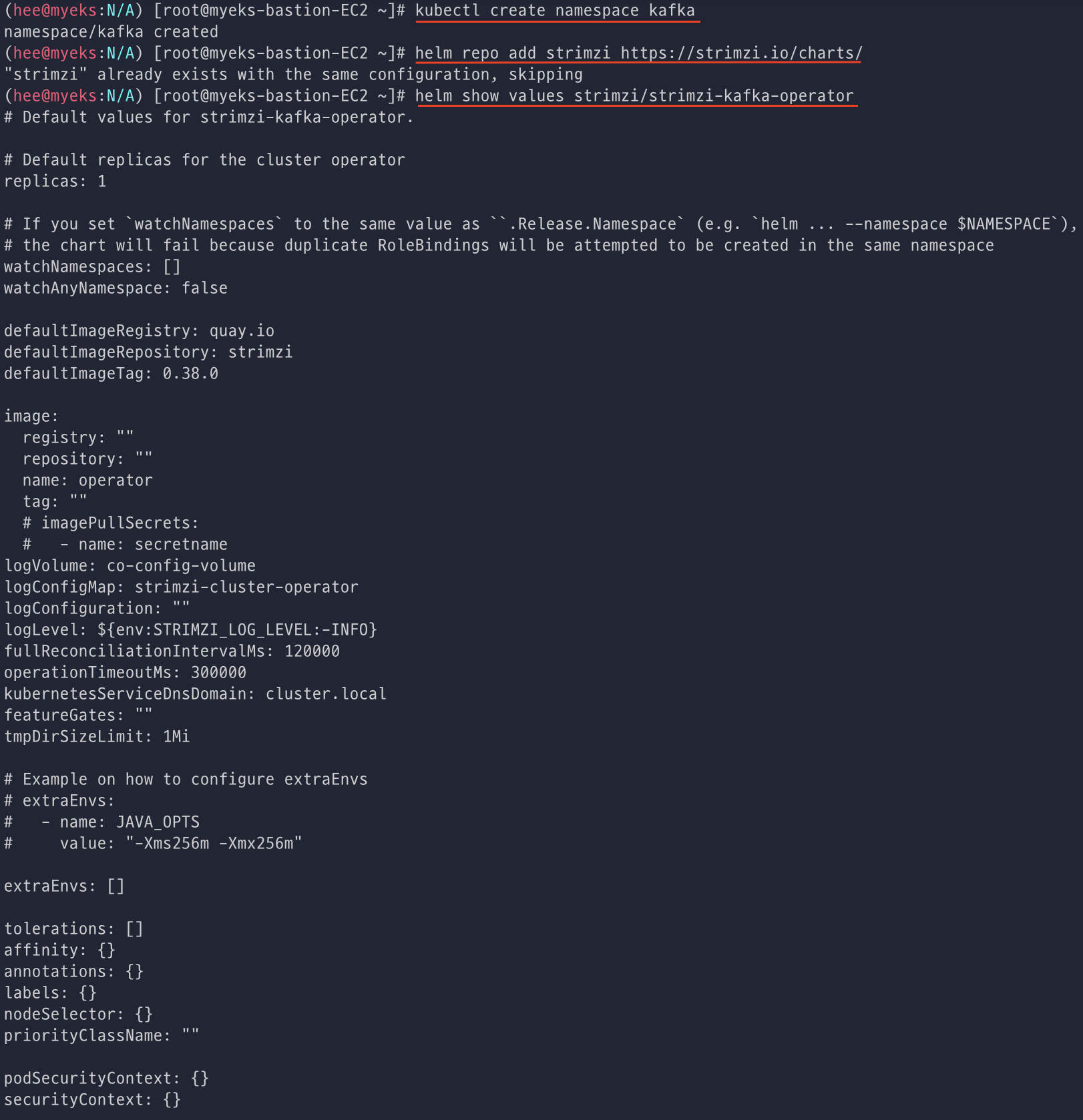
helm으로 kafka-operator 설치 후 deploy, pod를 확인해본다.

operator가 지원하는 kafka 버전 확인해본 뒤에 배포된 리소스도 확인한다.
그리고 CRD 상세 정보 확인할 수 있는 명령어도 사용해서 확인해보는 것도 좋다. (단, 너무 내용이 길어서 more나 옵션 사용 필요한 것 같다. 🧐)

# CRD 상세 정보 확인
kubectl describe crd kafkas.kafka.strimzi.io
Kafka 클러스터 배포 전에 log, pod, pv 등을 새로운 터미널에 모니터링 걸어 놓고 배포를 진행하였다. (pod 배포 전에는 1개였는데 배포 후에 캡쳐해서 3개로 보임)
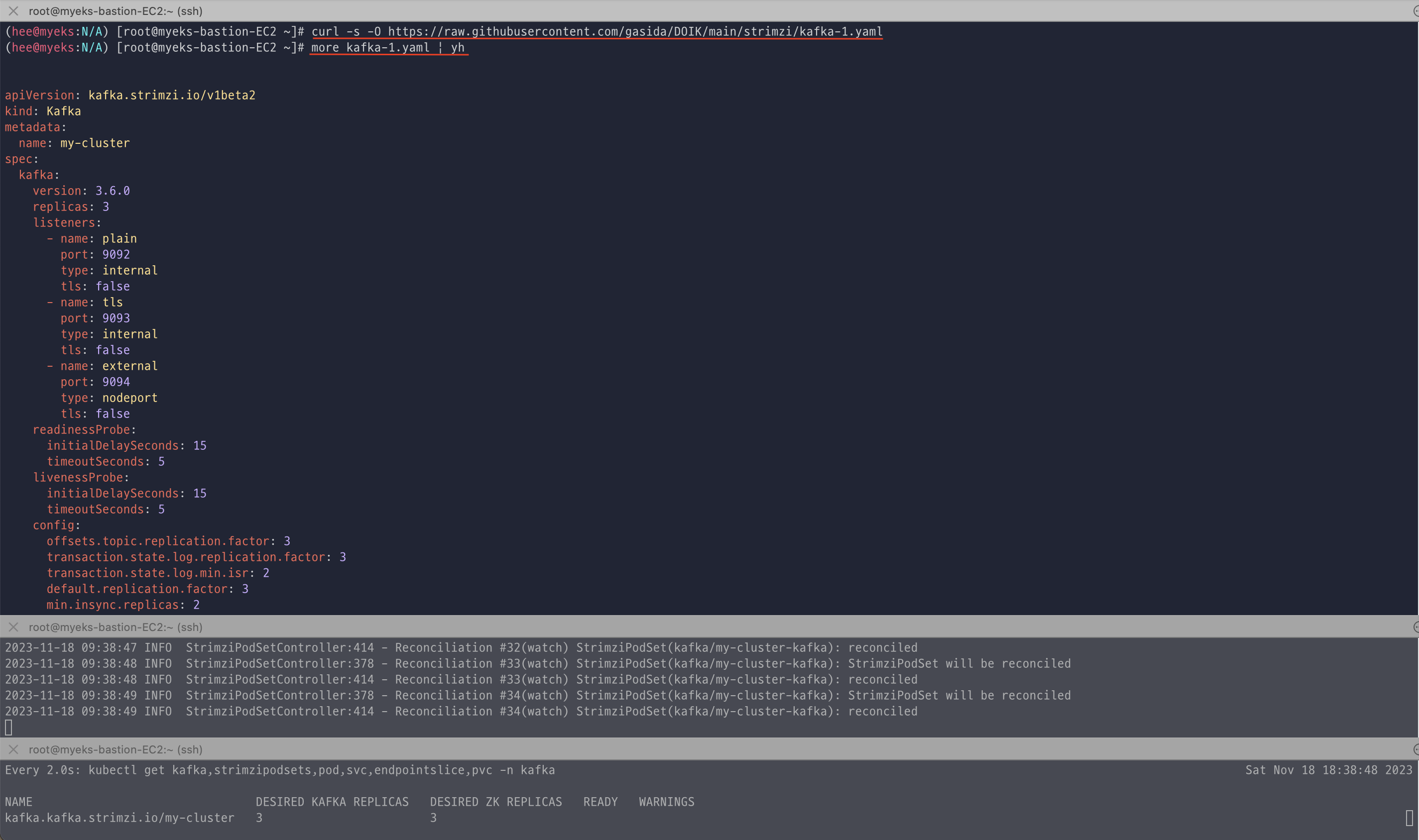
curl로 다운받은 클러스터 yaml 배포 진행 후 배포된 리소스들을 확인한다.

배포된 리소스를 확인하면 kafka, zookeeper strimzipodsets 생성 확인한다. (각각 3개가 배포 되었고, 상태가 READY가 맞는지 확인)
kafka configmap이 3개인 것은 각각 broker서버에 config를 다르게 사용할 수 있다고 볼 수 있다.

노드를 describe로 확인하니 Labels 값에 topology~로 시작하는 것도 확인 할 수 있다.
그리고 pv를 describe로 보면 Node Affinity에도 정보가 들어간 것을 볼 수 있다.


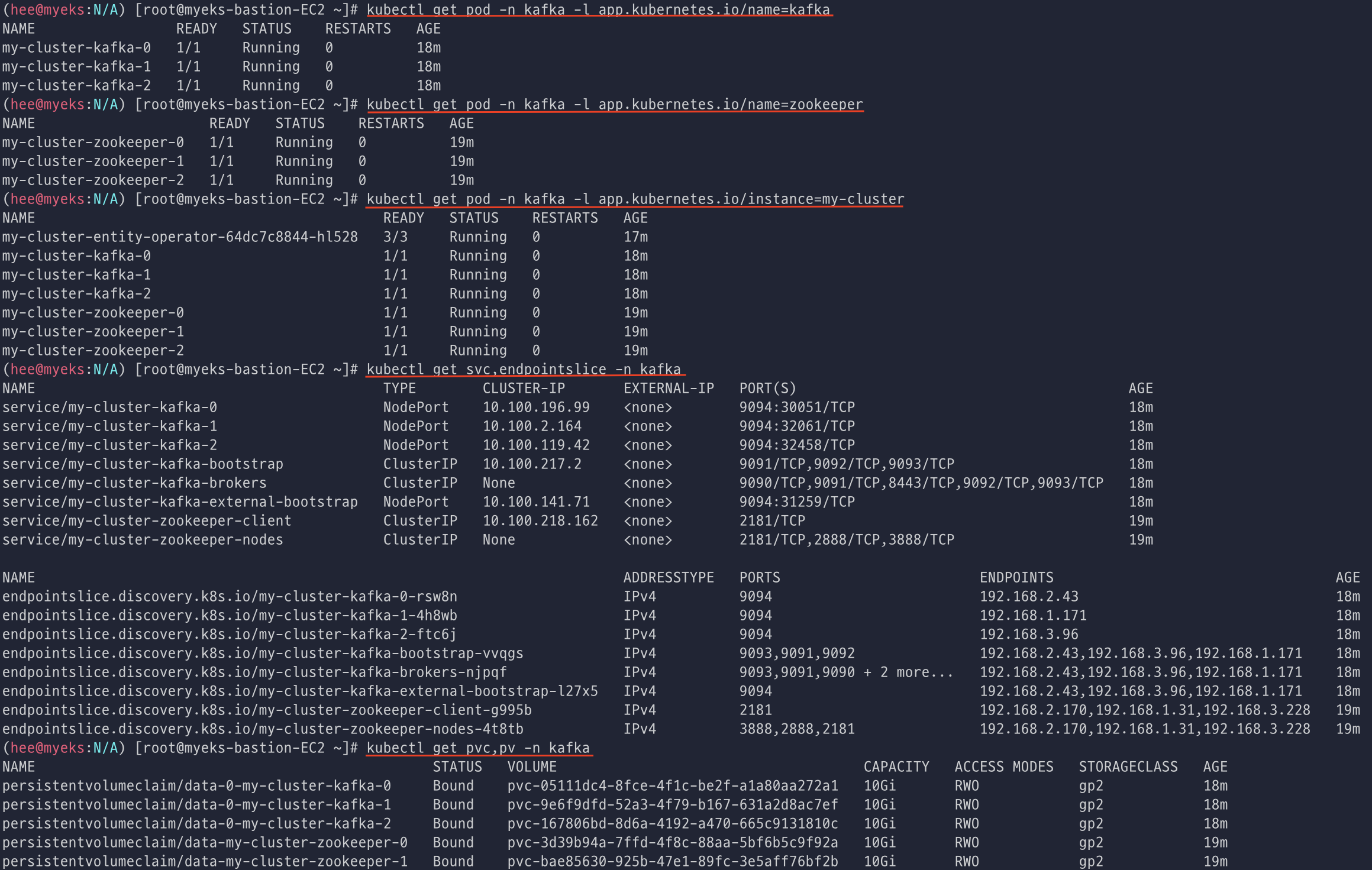
kafka, zookeeper Pod 확인 및 서비스 정보와 PV를 확인한다.
다양한 접속정보(Lisner)를 가지고 있는 것을 볼 수 있고, config map을 자세하게 보고 싶으면 아래 명령어를 사용해서 확인하면 된다.
kafka에 접속하는 정보(Lisner)를 볼 수 있다. (address: host, port)

kubectl describe cm -n kafka strimzi-cluster-operator
kubectl describe cm -n kafka my-cluster-zookeeper-config
kubectl describe cm -n kafka my-cluster-entity-topic-operator-config
kubectl describe cm -n kafka my-cluster-entity-user-operator-config
kubectl describe cm -n kafka my-cluster-kafka-0
kubectl describe cm -n kafka my-cluster-kafka-1
kubectl describe cm -n kafka my-cluster-kafka-2
테스트 pod를 만들어서 데몬셋으로 배포한 후에 확인하면 myclient pod가 생성된 것을 확인할 수 있다. (kafka client)
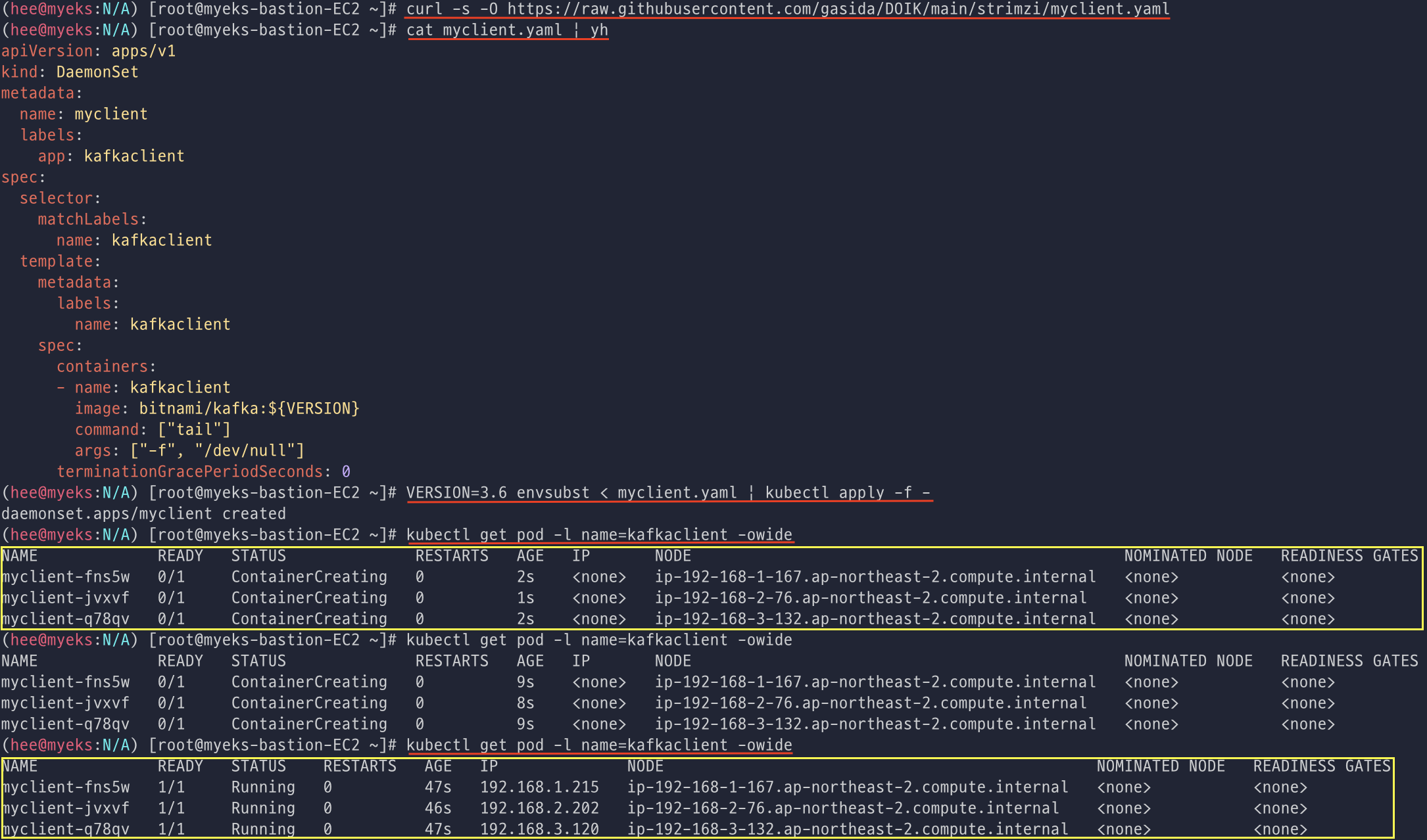
브로커의 정보 확인 시 3개의 브로커의 정보를 각각 보여주는데 굉장히 자세하게 알려준다. (내용이 엄청 많음...😩)

토픽(DB 스키마 같은 느낌) 리스트를 확인 및 kafkacopic을 한번 더 확인한다.

Topic 생성
토픽을 새로운 터미널에 모니터링을 걸어 놓고, 파티션 1개, replication 3개로 토픽을 생성하였다.
아래 모니터링 중이던 터미널에 mytopic1이 생성된 것을 실시간으로 볼 수 있었다.
그리고 생성된 토픽도 확인해본다. (상세 정보는 describe를 통해 확인해보면 됨.)


새로운 토픽을 하나 더 생성해서 정보를 확인한 뒤에 파티션을 기존 1개에서 2개로 증설을 하였다. (증설 후에는 파티션 개수를 줄이는 것이 불가능함.)
파티션 0번의 리더와 1번의 리더가 확인되고, 파티션 개수를 줄이려고 하면 아래와 같이 Error가 발생하는 것을 확인할 수 있다.


kafka min.insync.replicas=2 를 min.insync.replicas=3으로 변경도 진행해보고 다시 원복하였다.

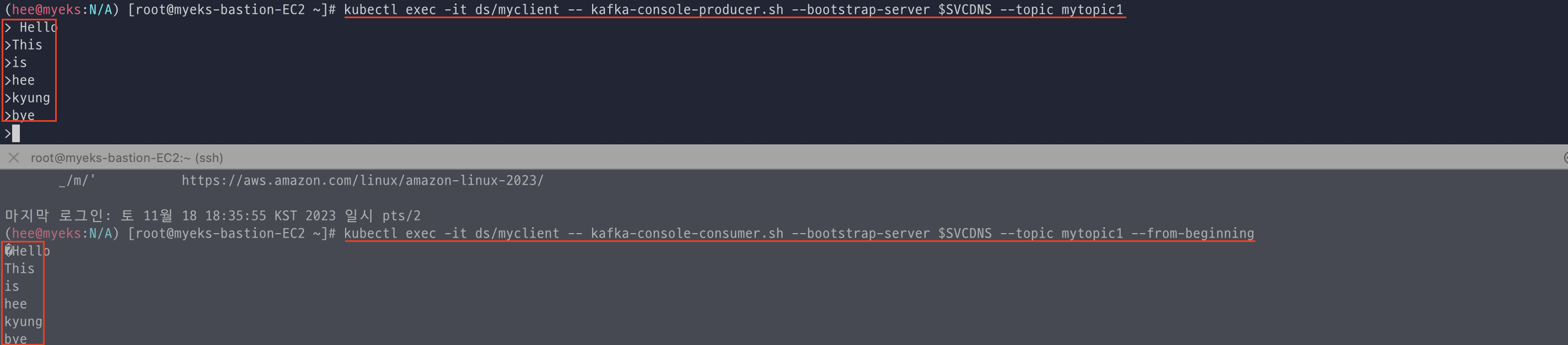
Topic 메시지 주고 받기
토픽에 메시지를 넣어주면 데이터를 그대로 동일하게 메시지를 가져간 것을 확인할 수 있다.
메시지 키:메시지 키값으로도 넣을 수 있다.
Kafkacat 사용해보기
node정보를 확인하면 external-bootstrap을 볼 수 있다. (접근해서 사용할 곳)
이 external-bootstrap svc는 kafka broker를 외부에 노출을 시킨 다음에 외부 어플리케이션에서 접근할 때 사용한다.
docker container로 kafkacat을 띄워 사용한다. (아마존 리눅스는 불편해서 docker로 실행하게끔 구성하셨다고 하신다.)
아 너무 슬프게도 내가 docker를 기동시키려고 하니까 에러가 나서 구글링하면서 ts하다가 시간이 없어서 다시 복습을 해봐야 할 것 같다. 😭 (서터레수😤)
다시 시도하고 정상적으로 되면 업데이트 하도록 하겠습니다...!!


# 장애 테스트
Topic을 하나 더 생성(파티션 1개 리플리케이션 3개, ISR=2)하고, 토픽 정보 확인하면서 컨트롤러 브로커 위치 확인한다.
(왜 또 docker 명령어를 사용하면 제대로 controller 값이 안나오는지 알 수가 없다. 네트워크가 문제인가 ts 대상 추가...)

터미널을 하나 더 추가해서 for문을 사용헤 메시지를 계속 넣고 한쪽에는 메시지를 잘 받는지 확인해봤다.
for문이 돌때마다 천천히 메시지를 잘 받는 것을 확인할 수 있다!

강제로 컨트롤러 브로커 파드 삭제하여도 메시지를 정상적으로 잘 받는지 확인하니, 메시지는 잘 받는 것을 확인하였다.
그리고 zookeeper도 삭제 해보았는데 처음에 잘 받는 거 처럼 보이다가 한 두개 정도 빠지고 다시 Pod가 정상적으로 올라오니 메시지가 잘 올라오는 걸 확인했다.


참고
https://kafka.apache.org/intro
https://www.ibm.com/topics/apache-kafka
https://engkimbs.tistory.com/entry/691
'CloudNetaStudy > [Study] DOIK' 카테고리의 다른 글
| [6주차] Stackable Operator (1) | 2023.11.25 |
|---|---|
| [4주차] Percona Operator for MongoDB (2) | 2023.11.06 |
| [3주차] Cloud Native PostgreSQL (0) | 2023.11.01 |
| [2주차] K8S Operator & Inno DB (0) | 2023.10.26 |
| [2주차] 실습 환경 세팅하기 (0) | 2023.10.25 |