이 글은 CloudNet@ 팀 gasida님의 스터디 DOIK 2기 내용 및 실습으로 작성된 글입니다.
What is MongoDB?

오픈소스 비관계형 데이터베이스 관리 시스템(DBMS)으로, 테이블과 행 대신 유연한 문서를 활용해 다양한 데이터 형식을 처리하고 저장한다. NoSQL 데이터베이스 솔루션인 MongoDB는 관계형 데이터베이스 관리 시스템(RDBMS)을 필요로 하지 않으므로, 사용자가 다변량 데이터 유형을 손쉽게 정리하고 쿼리할 수 있는 탄력적인 데이터 저장 모델을 제공한다. Mongo DB의 주요 기능 중 하나는 스키마가 있는 JSON과 같은 문서 형식으로 데이터를 저장하는 문서 지향 데이터 모델이다.
NoSQL
"not only SQL", "non-SQL"으로도 불리는 NoSQL은 관계형 데이터베이스의 전통적인 구조 밖에서 데이터 저장 및 쿼리를 가능하게 하는 데이터베이스이다. NoSQL은 여전히 관계형 데이터베이스 관리 시스템(RDBMS)에서 찾을 수 있는 데이터를 저장할 수 있지만 RDBMS와는 다른 방식으로 데이터를 저장한다.
NoSQL 데이터베이스는 JSON 문서와 같은 하나의 데이터 구조 안에 데이터를 보관한다. 비관계형 데이터베이스 설계는 스키마가 필요하지 않으므로 일반적으로 비정형인 대규모 데이터 세트를 관리할 수 있는 신속한 확장성을 제공한다.
NoSQL은 또한 분산 데이터베이스의 한 유형으로, 정보가 다양한 서버에 복제 및 저장되며, 데이터의 가용성과 신뢰성이 유지되고 데이터 중 일부가 오프라인 상태가 되어도 데이터베이스의 나머지 부분은 계속 실행될 수 있다.
NoSQL 데이터 베이스 유형
문서 저장소(Document Stroe), 키-값 저장소(Key-value), 열 지향 데이터데이스(Wide-Column Store), 그래프 저장소(Graph Store) 등의 유형이 있다.
1. 키-값 저장소(Key-Value)
일반적으로 NoSQL 데이터베이스 중 가장 단순한 형태이며, 스키마가 없으며 키-값 쌍으로 구성된 사전으로 조직화하여, 각 항목들은 키-값을 가지고 있으며, 단순하고 빠른 읽기와 쓰기가 가능하다.
키-값 저장소는 사용자 세션 정보를 캐시하고 저장하는데 대부분 사용하고 있으며, 한 번에 여러 레코드를 가져와야할 경우에 적합하지 않다.
Redis와 Memcached에서 사용중이다.
2. 문서 저장소(Document Store)
데이터를 문서로 저장하며, 준정형 데이터를 관리하는 데 유용하고 데이터는 일반적으로 JSON, XML 또는 BSON 형식으로 저장한다.
데이터가 애플리케이션에서 사용될 때 데이터를 함께 모아 데이터를 사용할 때 변환 작업을 하기 때문에 작업시간을 줄여준다.
문서 간 데이터 스키마(ex. name와 first_name)가 일치하지 않아도 되므로 개발자는 더 큰 유연성을 가진다. 이 특징은 복잡한 트랜잭션의 경우 문제가 될 수 있고 데이터 손상을 유발할 수 있다.
컨텐츠 관리 시스템 및 사용자 프로필에 사용하고 있으며, Mongo와 Couch에서 사용중이다.
3. 열 지향 데이터베이스(Wide-Column Store)
정보를 컬럼에 저장하므로 사용자는 관련 없는 데이터에 추가 메모리를 할당하지 않고 특정 컬럼에만 액세스할 수 있다. 키-값 저장소와 문서 저장소의 단점을 해소하기 위해 사용되지만, 실제 관리하기는 더 어려울 수도 있다.
소셜 네트워킹 웹사이트 및 실시간 데이터 분석 등 다양한 사용 사례에 사용되고 있다.
Apache HBase와 Apache Cassandra에서 사용중이며, Apache HBase는 희소성있는 데이터 세트를 저장하는 방법으로 제공되는 Hadoop Distributed Files System을 기반으로 구축한다. Apache Cassandra는 여러 개의 서버, 여러 데이터 센터를 포괄하는 클러스터링에 걸쳐 대량의 데이터를 관리하도록 설계 되었다.
4. 그래프 저장소(Graph Store)
일반적으로 지식 그래프의 데이터를 보관하며, 데이터 요소는 노드, 엣지, 속성으로 저장된다. 어느 객체, 장소 또는 사람이든 노드가 될 수 있으며, 엣지는 노드 간의 관계를 정의한다. 그래프 내 요소들 간의 연결 네트워크를 저장하고 관리하는 데 사용된다.
Node4j는 오픈소스 커뮤니티 에디션을 사용하는 Java 기반의 그래프 기반 데이터베이스 서비스이다.
NoSQL 특징
1. 스키마가 존재하지 않는다.
데이터에 대한 사전 정의가 필요하지 않아 데이터 모델링이 간단하고 유연한 데이터 저장과 검색이 가능하다.
2. 수평적 확장이 가능하다.
많은 서버를 추가하면서 데이터베이스 처리 능력을 향상시킬 수 있다. 대규모 데이터 처리에 유용하다.
3. 다양한 데이터 모델을 제공한다.
각각의 데이터 형식에 맞게 Key-Valume, Document, Column Family, Graph 등 다양한 형태의 데이터 모델을 제공한다.
4. 높은 가용성을 보장한다.
다수의 노드를 이용하여 데이터를 저장하므로, 한 노드가 다운되어도 다른 노드에서 데이터를 읽을 수 있다. 대규모 서비스에서 매우 중요한 요소 중 하나이다.
* 수평적 확장이란?
서버 수를 늘리는 것을 의미하며, NoSQL 데이터베이스에서는 데이터를 여러 노드에 분산하여 저장하고 처리하기에 시스템의 용량과 처리량을 확장할 수 있다.
* 수직적 확장이란?
서버의 성능을 향상시키기 위해 하드웨어를 업그레이드 하는 것을 의미하며, 일반적으로 CPU, Memory, Disk 등의 하드웨어 요소를 교체하거나 추가하여 시스템의 성능을 개선하는 방법이다.
◈ NoSQL의 수평적인 확장 방법
1. 샤딩(Sharding)
데이터를 파티션으로 나누어 여러 노드에 분산 저장하고, 각 노드는 자체 하위 집합 데이터를 관리하며 분산된 데이터는 전체 시스템에서 처리 됨.
2. 레플리케이션(Replication)
데이터를 여러 노드에 복제하여 저장하며, 데이터의 가용성과 내구성을 향상 시키는데 도움이 된다. 레플리케이션은 읽기 작업을 분산하여 처리하고, 장애 발생 시 데이터의 손실을 방지할 수 있음.
3. 로드 밸런싱(Load Balancing)
요청이 균등하게 분산되도록 트래픽을 조절하는 메커니즘을 구현하며, 이를 통해 각 노드의 작업 부하를 균형 있게 분산 시킬 수 있음.
4. 자동 스케일링(Auto Scaling)
시스템의 부하에 따라 자동으로 노드를 추가하거나 제거하여 수평적인 확장을 지원하고 대량의 트래픽이나 데이터가 발생할 때 유연하게 확장할 수 있는 장점이 있음.

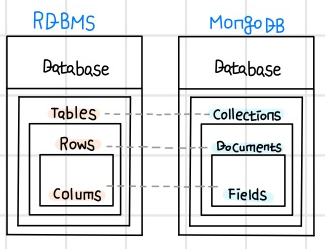
MongoDB 구조
MongoDB는 Documnet 기반 데이터베이스이며, Database > Collection > Document > Field 계층으로 이루어져있다. (계층은 RDBMS와 유사)
Database 공간에 여러 개의 Collection이 존재하고, 그 안에는 Document들로 구성되어있다.
MongoDB는 RDBMS와 다르게 자유롭게 데이터 구조를 잡을 수 있으며, JSON(BSON)으로 데이터가 쌓이기 때문에 Array 데이터나 Nested한 데이터를 쉽게 넣을 수 있다.

| MongoDB | 설명 |
| 컬렉션(Collection) | MongoDB 문서(Document)의 그룹으로, RDBMS에서의 Table과 유사 |
| 문서(Document) | MongoDB에서 데이터를 저장하는 단위로, JSON 형태로 저장되며 필드와 값의 쌍으로 구성 |
| 필드(Field) | 문서 내에서 데이터를 식별하는데 사용되는 이름 |
| 값(Value) | 문서 내에서 필드에 할당된 데이터 |
| 인덱스(Index) | 컬렉션 내에서 검색을 빠르게하기 위해 필드 값을 저장 및 정렬하는 데이터 구조 |
| 쿼리(Query) | MongoDB에서 데이터를 검색하는 명령어 |
* MongoDB의 아키텍처
1. PSA (Primary, Secondary, Arbiter)
PSA 아키텍처는 시스템에서 Primary node, Secondary node 및 Arbiter 역할을 하는 세 가지 주요 요소로 구성됨.
일반적으로 장애조치(Failover)를 처리하는데 효과적으로 많이 사용하는 아키텍처이다. (대표적임)
Primary Node가 정상적으로 작동하는 동안에는 Primary가 요청을 처리하고, Secondary Node는 주 서버의 복제 또는 대기 상태로 유지된다.
Primary Node 장애 시, arbiter에 의해 Secondary Node가 Parimary로 승격되어 요청 처리를 계속하고, 이러한 선정과정을 election이라고 한다.

2. PSS(Primary, Secondary, Secondary)
PSS 아키텍처는 Primary Node와 두 개의 Secondary Node로 구성되어있다.
PSA 아키텍처와 유사하지만 arbiter가 없어 가중치 없이 Secondary Node중에 하나가 자동으로 Primary Node로 승격된다.
실습
CRD 설치

mongodb cluster를 operator가 관리해서 생성되는 crd 가 확인된다.
psmdb라는 새로운 namesapce를 생성하여, 앞으로 생성되는 모든 pod 등은 psmdb라는 namespace를 기본적으로 사용하도록 설정한다.
보면 myesk뒤에 N/A로 되어있던게, psmdb로 변경된 것을 확인할 수 있다. (Default ns 변경)
RBAC 설치

Percona Operator에서 필요한 정책 및 권한 RBAC Role, Rolebinding을 설치한다.
Operator 설치


오퍼레이터의 경우 deployment로 구성하고 Pod까지 확인한다.


Cluster배포 전에 개인이 사용할 명으로 export후에 secret 생성한다.
secret 파일을 보면 우리가 사용할 계정 몇 개를 확인할 수 있다. 계정별로 권한이 상이하다. (Cluseter Admin, Database Admin, User Admin 등)
Cluster 설치


설치할 때 아래 watch로 pod, pv 등 모니터링을 걸어 놓은 상태로 cluster를 설치하면 Pod가 구성되는 과정, pv 구성 과정등을 거의 실시간으로 볼 수 있다.
pod/hee-rs0-0이 아마 parimary DB일것이고 그 뒤로 생성되는 rs0-1, rs0-2가 standby DB로 생각된다.


Mongodb는 statefulset을 사용하고 구성된 Pod, PV, SVC 등을 확인한다.
복제된 Pod들이 물리적으로 다른 zone에 pod가 생성될 수 있도록, anfiaffinity 옵션으로 배포하였다.

Node 정보 확인 및 mongodb의 버전 설치 리소스 등을 위와 같이 확인한다.
헤드리스 서비스 접속정보 확인


헤드리스 서비스 (service, endpoint) 확인 후 엔트포인트의 슬라이스 정보를 확인한다.
192.168.x.x로 확인되는 3개의 endpoint가 Mongo Pod의 IP 이다.
헤드리스 서비스 접속하기 위해 새로운 pod 하나를 배포해서 접근한다.
사용할 이름을 정의해주고, 확인하면 3개의 Pod IP를 확인할 수 있다.
헤드리스 타입도 확인할 수 있다.

Test 용 Pod 구성

Demonset으로 myclinet pod를 새롭게 배포하고, 새로운 터미널을 열어서 클러스터에 접속한다. (Admin_User)
demonset의 이름으로 mongo pod 실행하고, 실행할 때 user계정과 password 서비스로 (admin)으로 접근하면, Primary DB로 접근한 것을 확인할 수 있다. DB에 접속해서 database, user 정보 등을 확인한다. (위에서 보았던 기본 계정들의 정보를 확인할 수 있다.)

그리고 데이터베이스 유저를 한 개 생성하고, 복제 정보 확인을 해본다.

두 번째 터미널에서 Cluster user 계정으로 접근하면 복제 정보를 확인할 수 있다. 계정마다 허용되는 정책이 상이하다는 것을 알 수 있다.

세 번째 터미널에서 doik 클러스터로 접속한다.
doik로 데이터 베이스로 스위치하고, 테이블을 생성하고 확인해본다.
그리고 insert로 데이터를 넣고, 해당 데이터를 조회하여 확인하고, 통계 정보를 한번 확인해본다.
drop으로 테이블을 삭제하고 데이터가 정상적으로 삭제되었는지 확인해본다.

Create 생성 테스트를 진행하였다.
처음에 콜렉션을 생성하고, Document를 입력해준 뒤에 내가 입력한대로 데이터가 들어갔는지 확인해준다.
그리고 파이썬의 List [] 문법을 사용하여 추가적으로 데이터를 더 넣어봤고, 내가 create한 4개의 데이터를 확인할 수 있었다.

복제 set 확인
3개의 터미널에 각각의 user로 cluster 접속을 한다.

Cluster User 가 있는 두 번째 터미널에서 복제 셋 정보 및 상태를 확인한다. (좀 많은 데이터를 확인할 수 있음.)


그리고 오피로그 정보(크기, 시간, 연산 등)을 확인할 수 있고 동기화 상태 확인(쎄컨더리 DB 구성원이 프라이머리 DB의 어디까지 정보를 동기화했는지 확인)하고, 복제 옵션 정보도 함께 확인한다. (이것도 데이터가 꽤 나온다.)

오피로그를 상세하게 확인하려면 local로 스위치하고, oplog에 관련된 사이즈를 확인하고 oplog데이터를 확인해본다.
상태 정보와 코드 정보 등을 아래와 같이 확인할 수 있다.

복제테스트를 진행해봤으며, 3개의 터미널을 열어 놓고 테스트를 진행했다.
첫 번째는 서비스 없이 mongo db(rs0-0)으로 접근하였고, 두 번째는 shell로 접속한 뒤에 변수 지정 후 rs0-1, 세 번째는 rs0-2로 접근하였다.
doik db의 count를 출력하면 현재 정보는 1개로 확인된다. while 문으로 실시간으로 count하게 한 뒤 첫 번째 터미널에서 데이터를 insert 한다.
그러면 실시간으로 복제의 개수가 올라가는 것을 확인할 수 있다.

[장애 테스트1] Primary Pod 강제 삭제
Primary Pod를 강제로 삭제할 경우 어떤 Secondary에서 Primary가 되는지 확인해보자.
Primary Pod를 삭제하면 클러스터 상태의 변화가 확인된다.
그리고 r0-1 Pod가 Primary로 승격된 것을 확인할 수 있다. 시간이 조금 지나면 rs0-0 pod도 다시 running 되어 primary 1개와 secondary 2개를 확인할 수 있다.


- 감기로 인한 컨디션 난조로 내용이 부실한 점 양해부탁드립니다...🥹
참고
https://appmaster.io/ko/blog/monggodibiran-mueosinga
https://www.ibm.com/kr-ko/topics/mongodb
https://adjh54.tistory.com/257
https://velog.io/@suhongkim98/MongoDB-%EA%B8%B0%EB%B3%B8
https://www.oracle.com/kr/database/nosql/what-is-nosql/
'CloudNetaStudy > [Study] DOIK' 카테고리의 다른 글
| [6주차] Stackable Operator (0) | 2023.11.25 |
|---|---|
| [5주차] Kafka & Strimzi Operator (0) | 2023.11.17 |
| [3주차] Cloud Native PostgreSQL (0) | 2023.11.01 |
| [2주차] K8S Operator & Inno DB (0) | 2023.10.26 |
| [2주차] 실습 환경 세팅하기 (0) | 2023.10.25 |